基于OceanGPT·沧渊微调定制知识增强问答引擎
今年暑假在张宁豫老师实验室实习,为实验室的oceangpt海洋大模型设计知识增强问答引擎
研究背景
-
几百页的船只操作手册,翻阅耗时又枯燥,关键细节常被遗漏;
-
碰到海洋新政策、新法规、新装备,信息分散、更新滞后,不知道去哪儿找;
-
现有大模型“盲区多”,本地部署难、行业知识少,无法满足企业级安全与隐私需求。
实现流程
- 模型获取
- HuggingFace下载预训练OceanGPT模型
*OceanGPT-basic 在 Qwen3 基础上,使用海洋专业的中英文数据集进行领域适配训练
- EasyDataset 开源工具使用
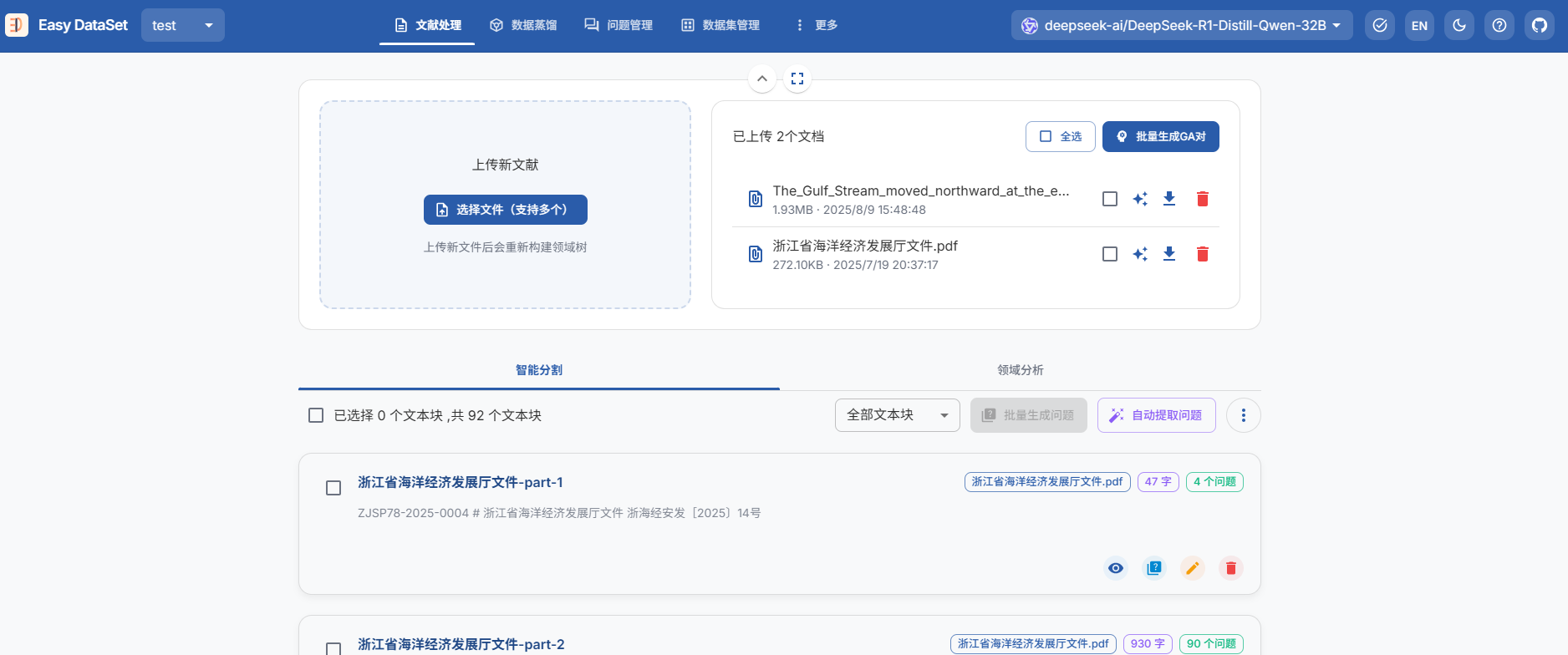
流程:上传PDF文件处理为文本块–>生成QA对–>导出数据集(sharegpt/alpaca格式)
-
Llama Factory 进行领域微调
LLaMA Factory 是一个开源的低代码微调框架,通过Web UI界面支持无需代码即可对大型模型进行微调。
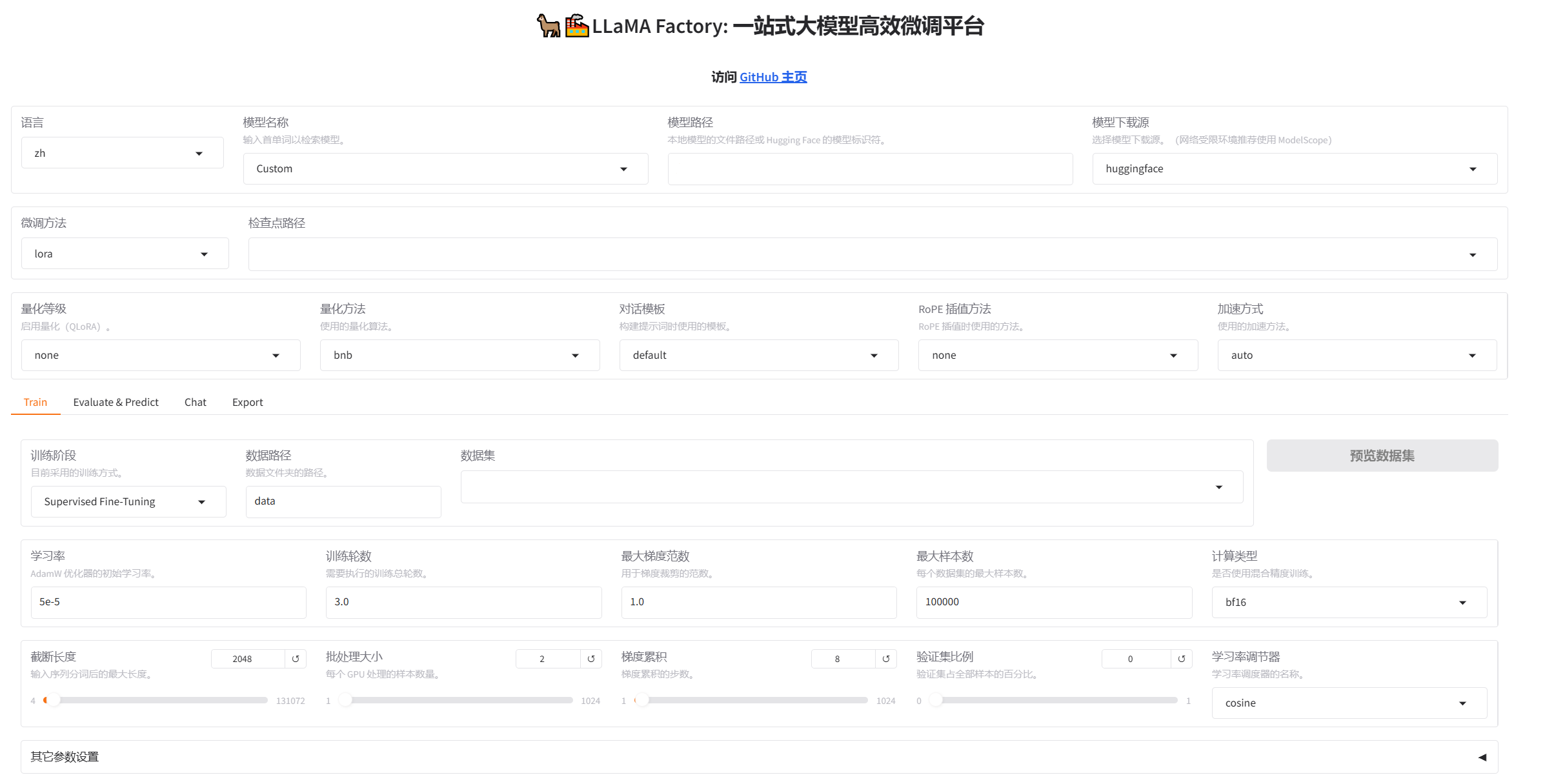
用生成的数据集对模型使用lora进行微调
TODO 学一下lora原理、微调参数影响
-
使用LangChain+Streamlit 搭建Web应用
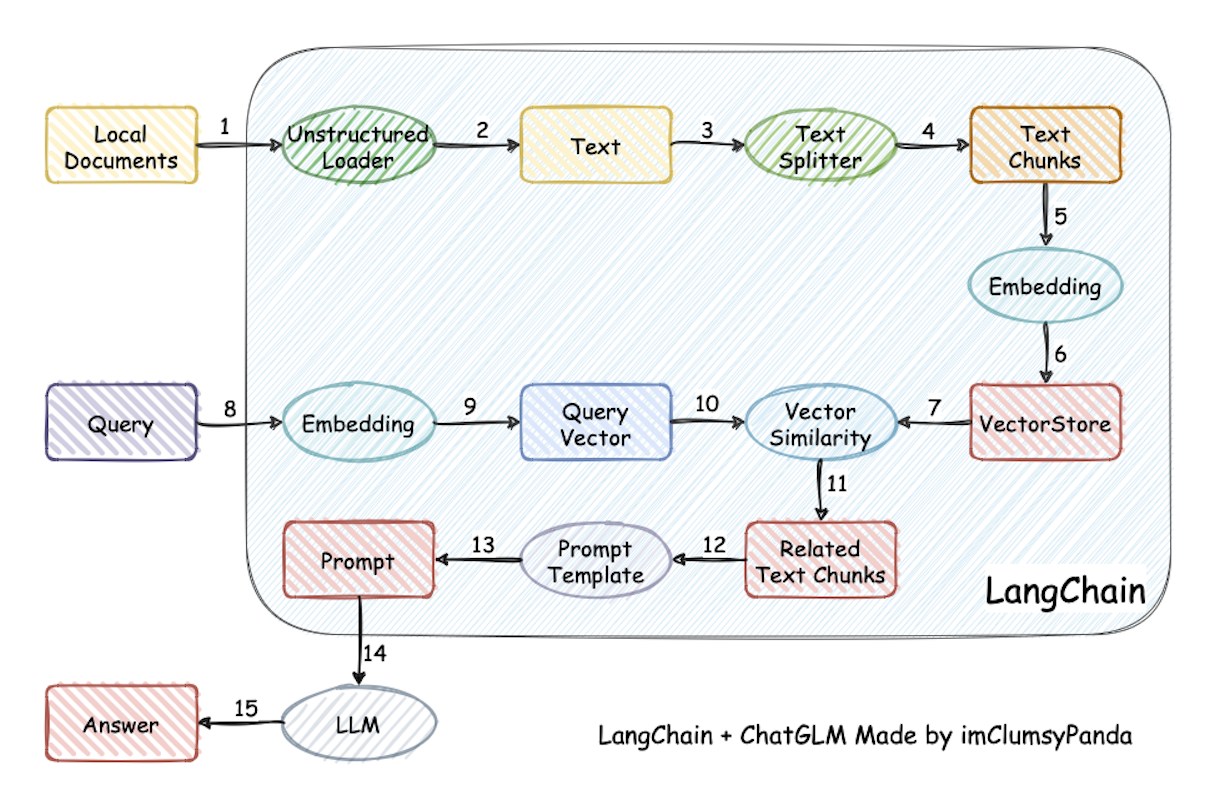
-
将本地量化大模型 (OceanGPT-LoRA) 与 LangChain 框架深度结合
-
使用了 4bit 量化(BitsAndBytes + LoRA)方法,在本地 GPU 上部署大模型,兼顾性能和资源消耗。
-
通过 LangChain 的
retrieval_chain构建端到端的 RAG 管道,让用户问题先经过向量检索,再由大模型结合检索到的上下文生成答案。 -
基于 Streamlit 开发对话式 Web UI,支持上传文档、清空历史、展示答案溯源(参考来源)。
-
向量化检索:采用 HuggingFace 的
all-mpnet-base-v2嵌入模型,结合 FAISS 搭建向量数据库,实现高效相似度检索。
get_pdf_text函数:提取文字,PyPDF2的PdfReader
get_text_chunks函数:分割成带元信息的文本块,text_splitter = RecursiveCharacterTextSplitter(chunk_size=512, chunk_overlap=64)递归分割,分割字符列表[“\n\n”, “\n”, “ “, “”]
get_vectorstore函数:加载embedding模型all-mpnet-base-v2,vectorstore = FAISS.from_documents(docs_chunks, embedding=embeddings)存储为向量
load_cached_model函数:加载oceangpt模型,从transformers库导入 AutoTokenizer(分词器), AutoModelForCausalLM(识别模型本地参数,加载模型), BitsAndBytesConfig(用于量化)
-
效果验证
- 在 GPU 显存有限的环境下,利用 4bit 量化方案,实现了大模型的流畅推理。显存使用:16GB->8GB
- 通过典型案例进行微调前后、有无RAG效果对比测试:实现了较高的回答准确性,并显著降低了“大模型幻觉”现象