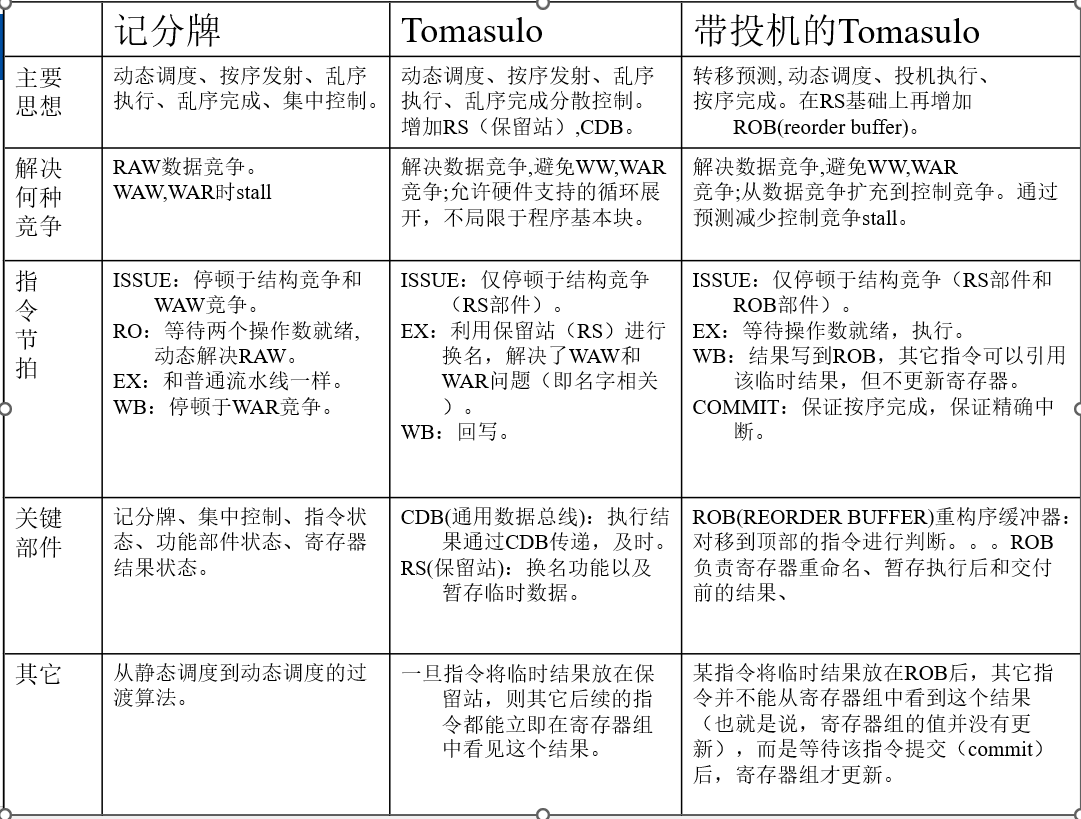
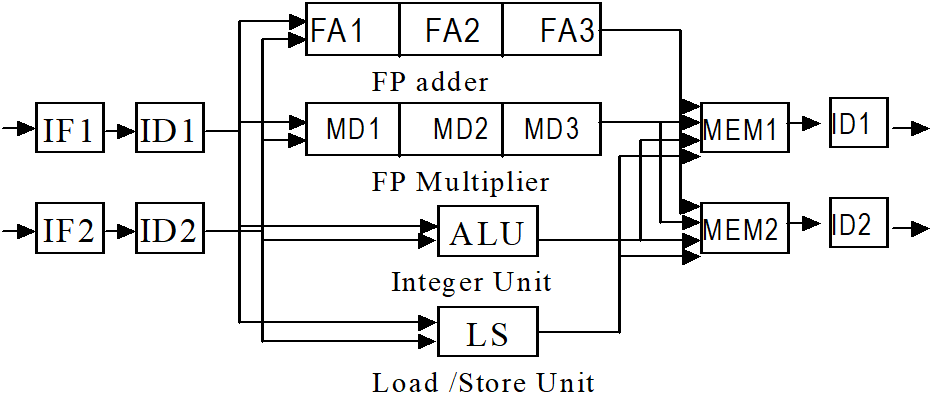
ScoreBoard
计分板结构
Instruction Status
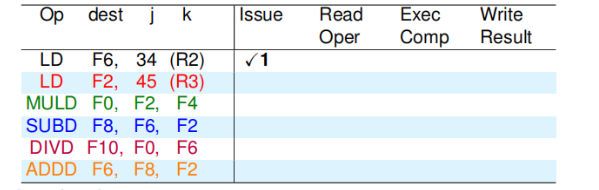
Function Unit Status (FUS)

在记分牌中每一个功能部件都有一组信息.
- 部件是否正在忙(Busy)
- 部件执行的指令类型(op)
- 部件需要的源寄存器(Fj/k)
- 目的寄存器(Fi)
- 源寄存器是否准备好(Rj、Rk 表示)
- 如果源寄存器没准备好部件该向哪里要数据(Qj,k)
Register Result Status (RRS)

记录对于某一个寄存器,是否有部件正准备写入数据
栏中的信息写具体的功能部件
整体架构
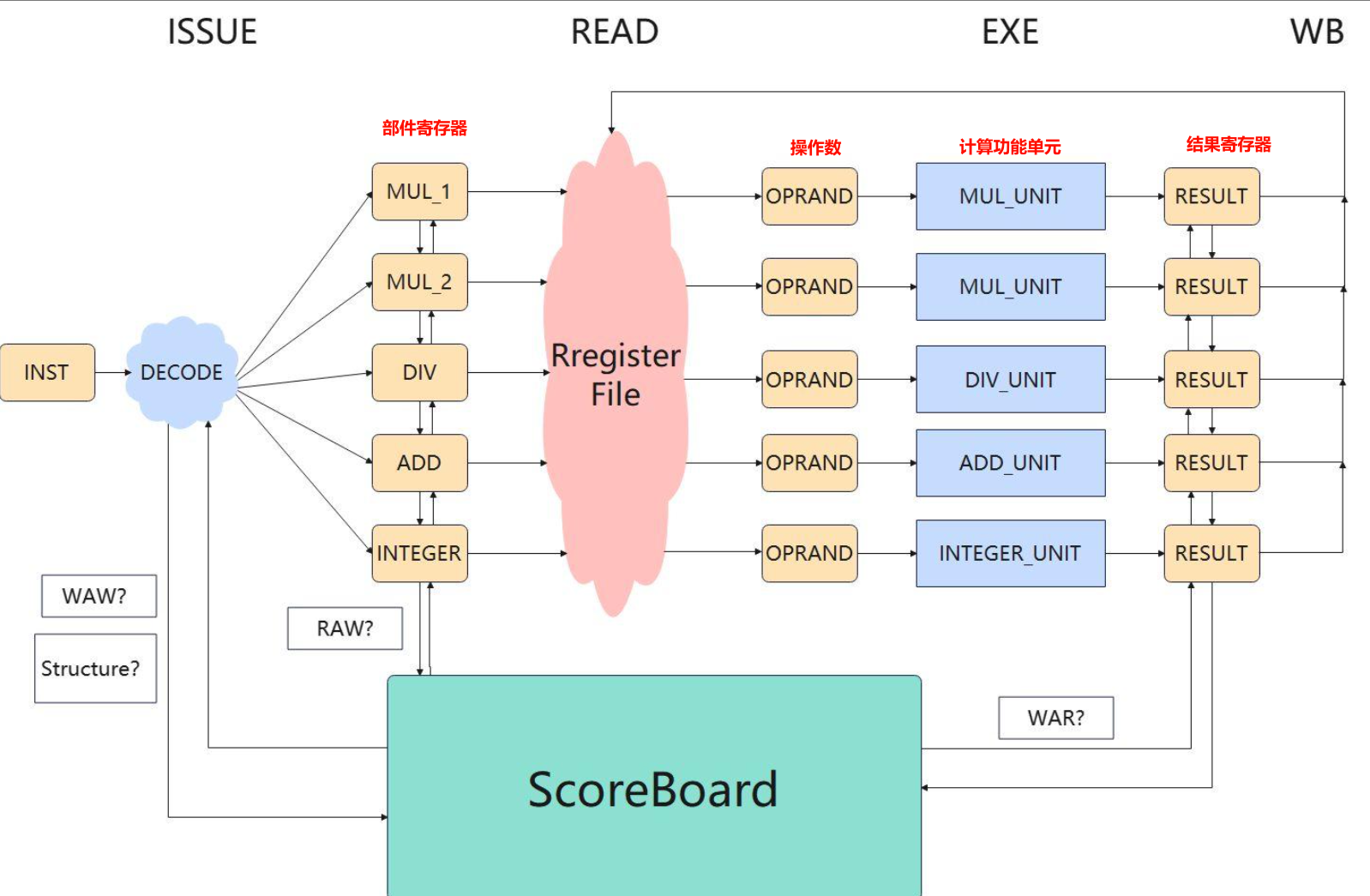
算法流程
IS阶段
对指令进行解码,并观察记分牌信息
如果
-
指令对应的功能部件空闲,
-
且指令要写的目标寄存器没有别的指令将要写(WAW 冒险)
那么阶段结束的时候,就可以把
- 指令信息存进部件寄存器
- 同时改写记分牌,三个表都要写(这时就判断寄存器的值是否准备好,Rj、Rk是Yes or No,写对应的Qj、Qk)
Read Operands阶段
检测两个寄存器的数值是否准备好。如果
- 数值没有准备好(这是为了解决 RAW 冒险),那么指令就卡在部件寄存器中,无法读取数据。
如果寄存器都可以读取,那么此阶段结束的时候
- 对应的寄存器数值会被存进操作数寄存器中,这里会改写记分牌(Rj、Rk改写为NO)。
EX阶段
执行计算过程,计算过程可能维持很多个周期。
WB阶段
此时需要观察记分牌,如果别的指令不需要读当前计算结果即将写入的寄存器(WAR 冒险,如果其他部件相关寄存器的 Rj、Rk 是 Yes ,那就说明有指令要读当前要写入的寄存器,要先等指令读完寄存器再写回)周期结束时,就会把结果写回到寄存器堆,同时会清空记分牌中的信息。
评价
缺点
- 只是遇到数据竞争就stall,并没有真正的解决。
- 碰到WAW,WAR还在等
- 功能单元数量不足会引发结构性冲突,阻碍指令并行化。
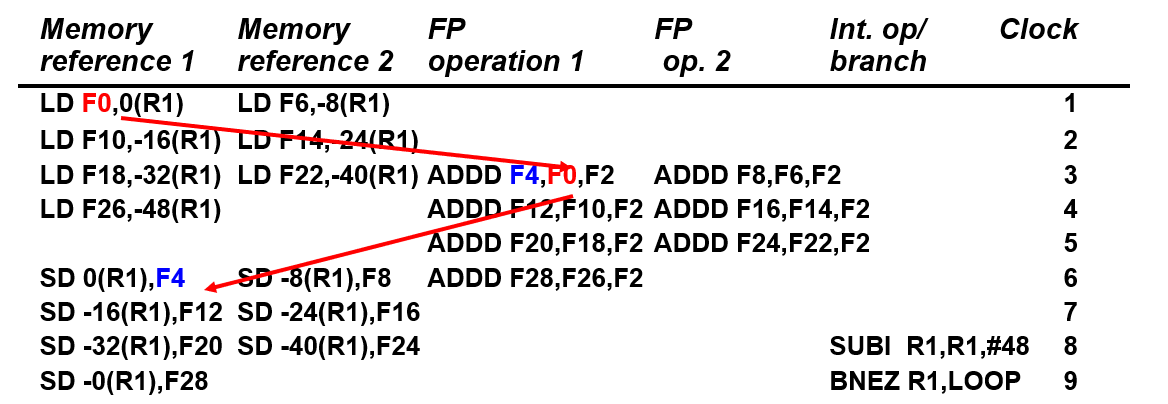
Tomasulo
总体结构
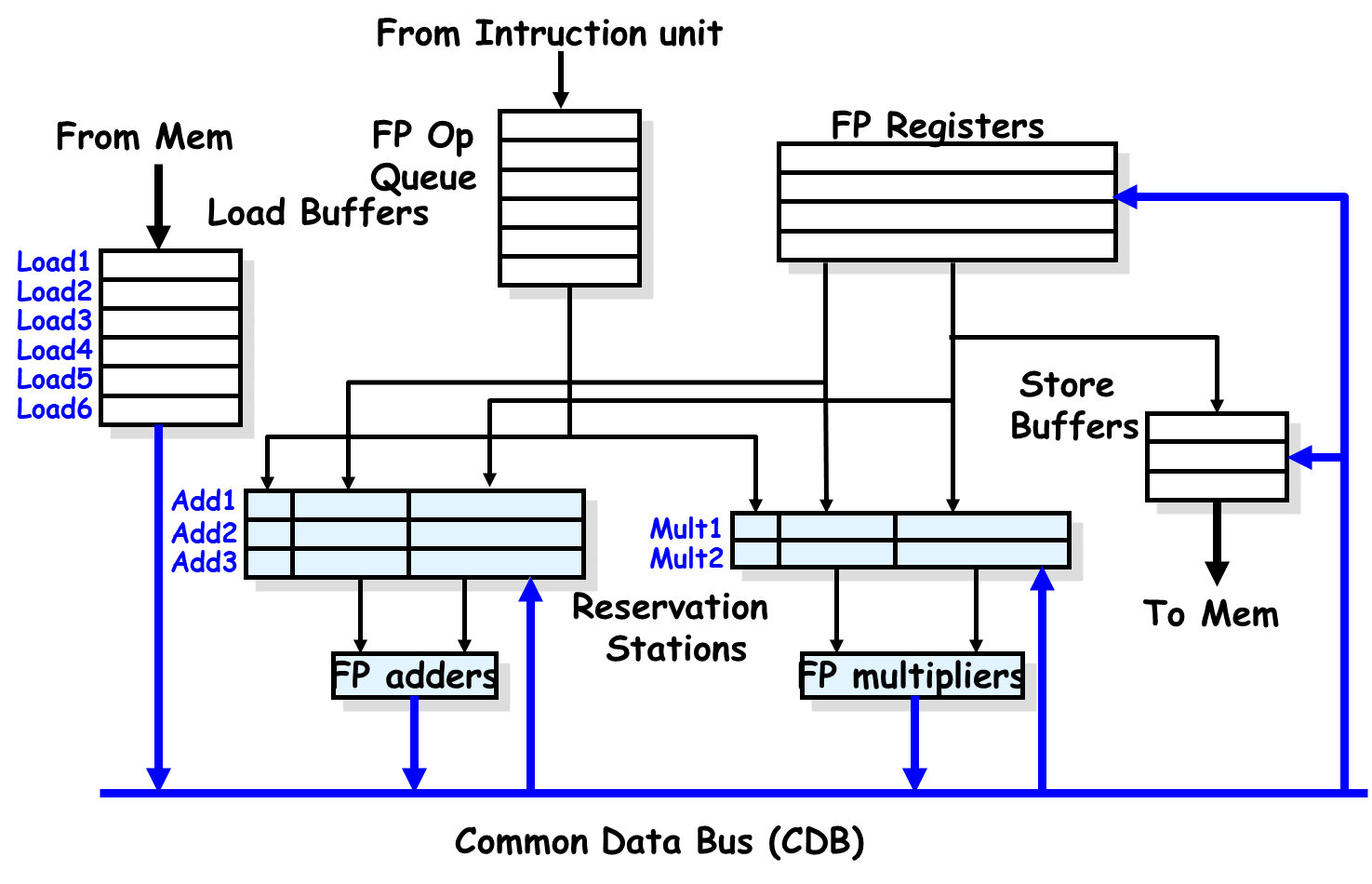
与ScoreBoard相比:
- 增加CDB通用数据总线(从保留站接收数据,送回保留站、寄存器或者存储器)
- 把FUS换为保留站
内部结构单元
Instruction Status
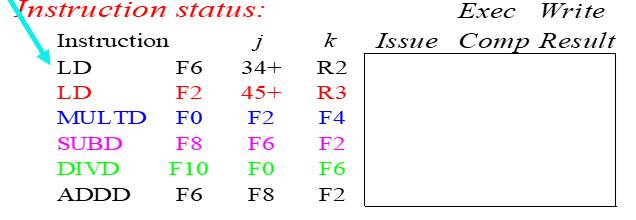
- Issue:get instruction from FP Op Queue
- Exec:如果两个源操作数都有值,直接执行。否则,监控是哪个保留站在写这个寄存器
- WB: write on Common Data Bus to all awaiting units; mark reservation station available
Reservation Stations and Load Buffers
是加减法和乘法指令的保留站

- op:指令需要进行的操作
- Vj/Vk:源操作数的值
- Qj/Qk:某个保留站的名字(如果源寄存器没准备好部件该向哪个保留站要数据)
- BUSY:是否忙碌
- A:如果是load store指令,放地址计算的值,hold info. for memory address calculation
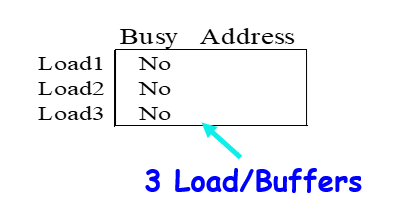
- 可以看作Load和Store的保留站
例如:LD F6 34(R2)
发射时写入buffer的是:
yes,R2的值+34(具体的地址)
Register result status

- 每个寄存器正在被哪个保留站写
执行流程
IS
只要保留站有空位,就能发射。并且更新保留站,寄存器结果状态表的值
-
检查源操作数是否准备好:
-
如果准备好,直接写入源寄存器的值
-
没有准备好,查看哪个保留站正在计算它的结果,记录该保留站的名字并通过CDB持续监控
-
-
寄存器结果状态表中相关目的寄存器的值 直接更新为 当前保留站
EXE
检查所有的源操作数是否准备好,准备好了就可以进行计算(scoreboard是直接exe),否则卡在IS阶段,监控是哪个保留站在写这个寄存器,如果相关保留站完成WriteBack,则接收数据,下一周期继续执行
可能执行多个周期
WB
计算完成直接写回,不用考虑其他的
阶段结束时:
- CDB更新寄存器的值
-
清空保留站
- 通过CDB通知所有等待目的寄存器的保留站,可以读取我的数据继续执行了(此阶段这些保留站的VjVk更新为相应的具体值,清空Qjk,下一阶段就可以进行exe计算)
评价
优点:
- 消除WAW,WAR,且不用刻意等待(寄存器重命名)
缺点:
- 不能很好解决控制竞争(scoreboard也是)
- 乱序执行,不能实现精确中断
Tomasulo with Reorder Buffer(Speculative Tomasulo)
总体架构
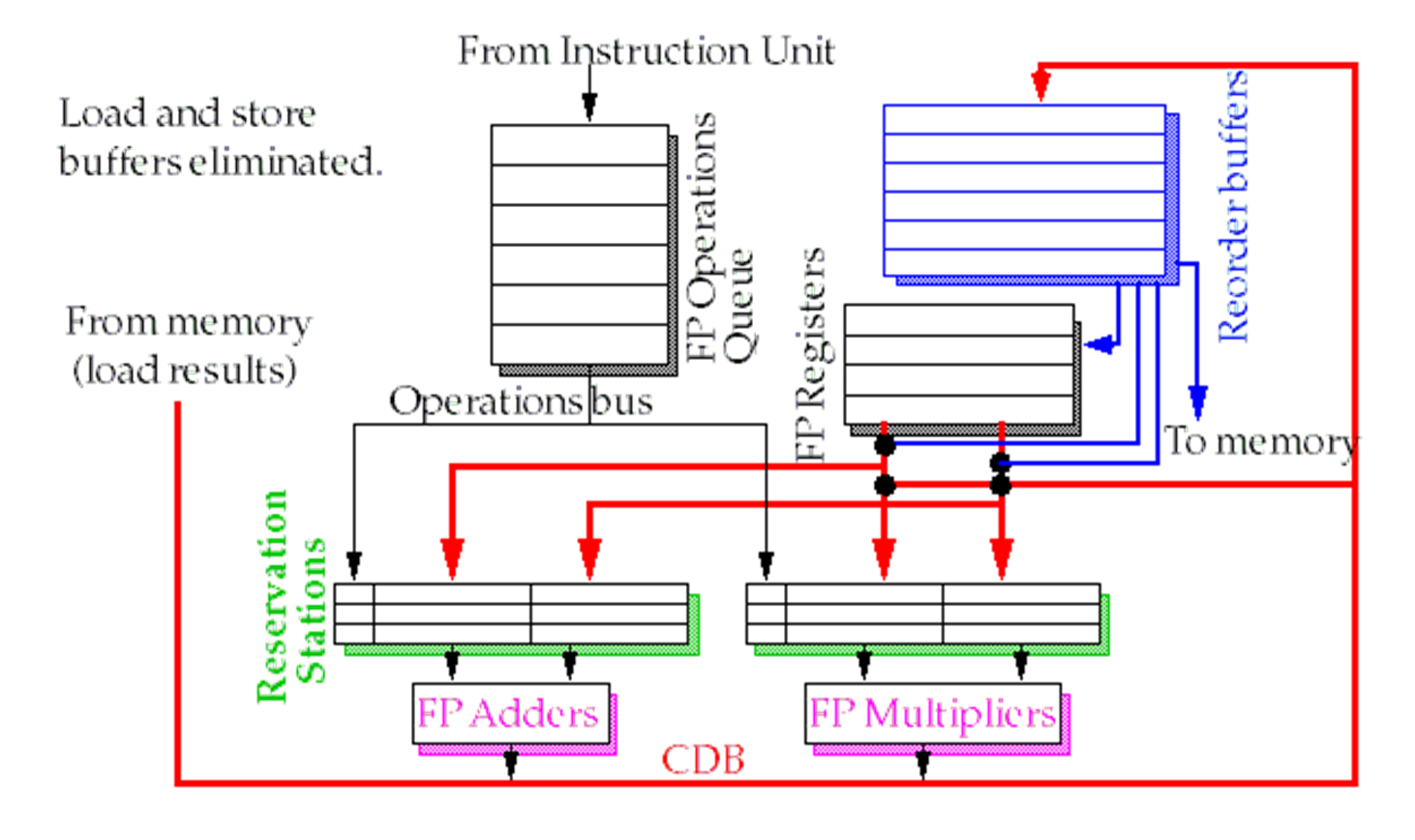
- 相比之前的Tomasulo增加了Reorder Buffer
- 写回时不能直接写回寄存器堆,需要先写到ROB,再由ROB决定顺序提交
- 发射时,将指令信息按顺序写到ROB中
- 重命名是通过ROB实现的
内部结构
Reorder Buffer

buffer内一行的信息包括
- 指令类型
- 源操作数、目的操作数
- Ready
- 值域
指令发射会同时发到ROB和RS保留站中,其中ROB底部的指令是老指令,往上是新指令(保证commit顺序)
其他结构和正常 Tomasulo 一样
加减法、乘法保留站,存储buffer(LoadStore保留站)
执行流程
IS
get instruction from FP Op Queue
只要相应的保留站和ROB有空位,就可以发射,同时发到ROB和RS保留站中。
- 如果能取到操作数的值,直接写值
- 没准备好值,将正在写这个寄存器值的ROB编号写入(重命名)
Exe
-
和正常 Tomasulo 一样,检查所有的源操作数是否准备好,准备好了就可以进行计算
-
否则卡在IS阶段,持续监听CDB,如果相关ROB完成WriteBack,则接收数据,下一周期继续执行
WB
-
计算完直接写回到ROB(不是寄存器堆),包括值域更新和Ready置为Yes
- 通过CDB总线传给正在等待这个ROB的保留站(如果有)
- 更新相关保留站的源寄存器的值(如果有)
- 清空这条指令的保留站信息
Commit
- ROB底部的指令如果Ready=Yes,可以commit。不是底部的,就算Ready也不能commit(保证按序提交)
- 如果不是分支跳转指令,直接commit
- 如果是跳转,且预测成功,commit
- 如果是跳转,且预测失败,清空所有的ROB,重新取指令
- 如果正常commit,写结果到寄存器堆,清空ROB这一行
特殊情况:
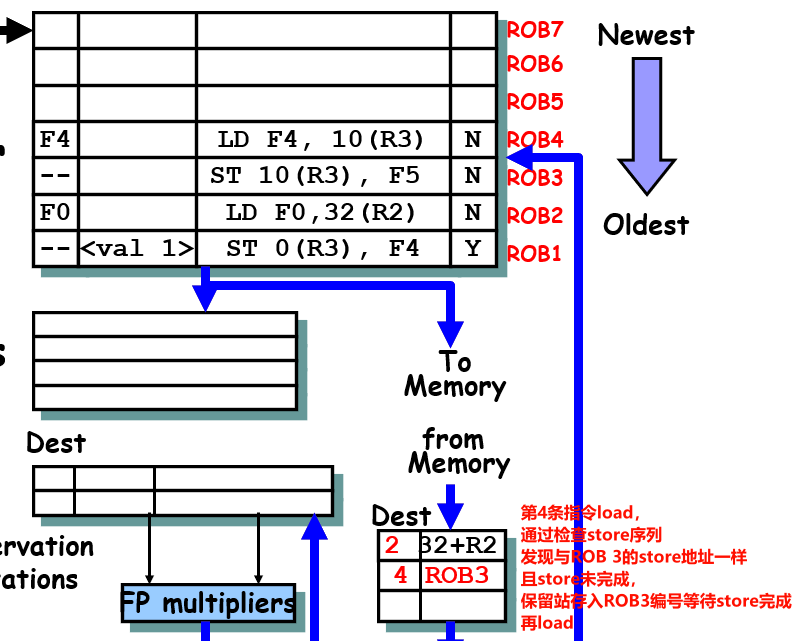
如果 Load 的地址与 Store 队列中一个较早 Store 指令的地址匹配,则发生 RAW 冲突
-
Store 的值已可用
如果 Store 的值已经计算完成,则可以直接将值从 Store Queue 返回给 Load,而无需等待实际写入内存。这是一种 旁路转发(Bypassing or Forwarding) 技术。
-
Store 的值尚不可用
如果 Store 的值还未计算完成,则无法完成 Load。此时,Load 将记录 Store 的 ROB编号作为数据来源,并等待 Store 指令完成。
下面是例子:
评价
- 按序提交,精准中断
Dynamic Hardware Prediction
1-bit Branch-Prediction Buffer
1kb大小的预测器,有1024个入口,每个入口有1bit预测。
通过指令地址后10位进行索引,索引到的入口用来预测此指令的跳转情况,如果预测失败,值翻转
in a loop, 1-bit BHT will cause 2 mispredictions ,n-2次预测成功
2-bit Branch-Prediction Buffer
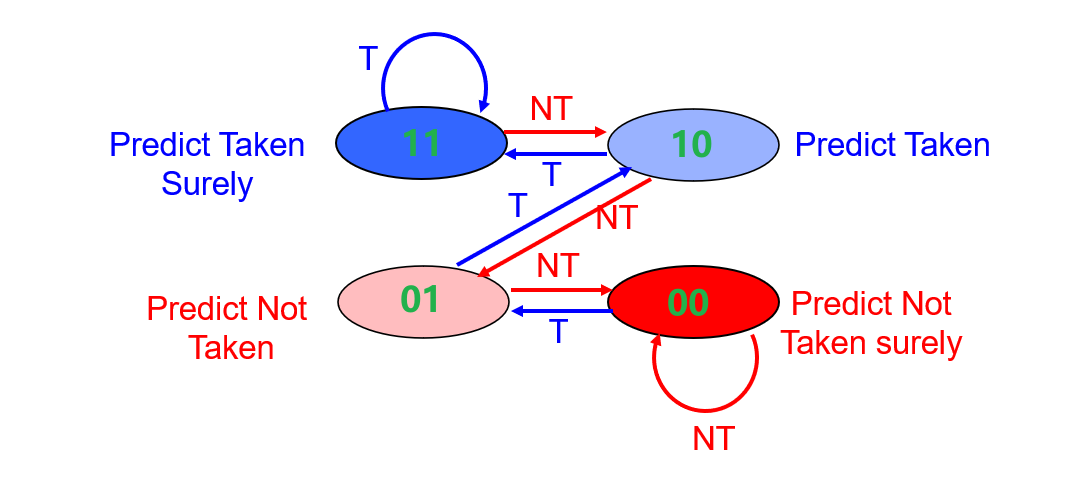
- 只有连续两次预测失败,才会改变预测的状态
- 00和11状态是稳定的,01,10状态是不稳定的
不是bit越多,效果越好的!增加入口数,效果没有明显提升。
Correlating Branches prediction buffer
引入
1
2
3
4
5
6
7
if ( aa == 2)
aa = 0;
if ( bb == 2)
bb = 0;
if (aa == bb ) {
……
}
考虑以上代码预测的内部联系,如果使用1位预测器,那么所有的预测都会失败
那么引入Correlating Branches prediction buffer,两个预测器结合的预测器
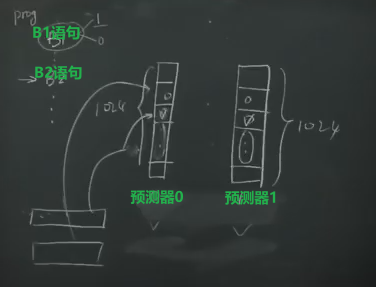
- 每一条预测语句对应两个预测器的一共两位
- 看前一条语句转移情况,如果上一条语句T 转移,选择第二个预测器的位,否则第一位
用这种预测器分析一开始的c语言代码:
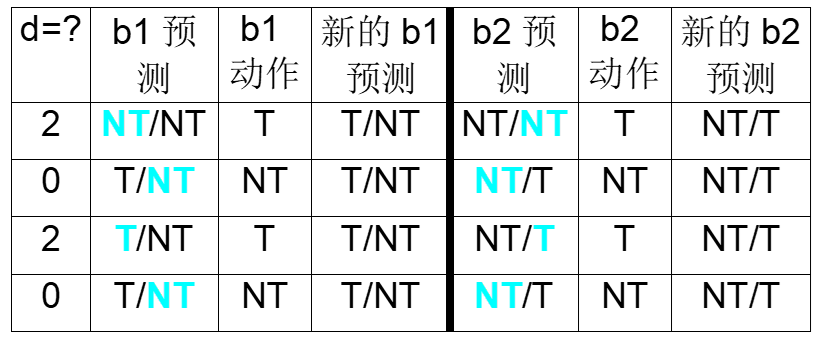
分析:
-
b1语句初始两位预测都是0、0,看第一位(因为前一条语句没有),预测不跳转,b1真实是跳转,预测失败,修改第一位为1
-
b2语句初始两位预测都是0、0,看第二位(因为前一条语句是T),预测不跳转,b2真实是跳转,预测失败,修改第二位为1
-
b1语句现在两位预测是 1、0,看第二位(因为前一条语句是T),预测不跳转,b1真实是不跳转,预测成功,不做修改
-
b2语句现在两位预测是 0、1,看第一位(因为前一条语句是NT),预测不跳转,b2真实是不跳转,预测成功,不做修改
Prediction with correlating predictor (m,n)
$2^m$个预测器,每个预测器有n位,表示根据前m条语句进行预测
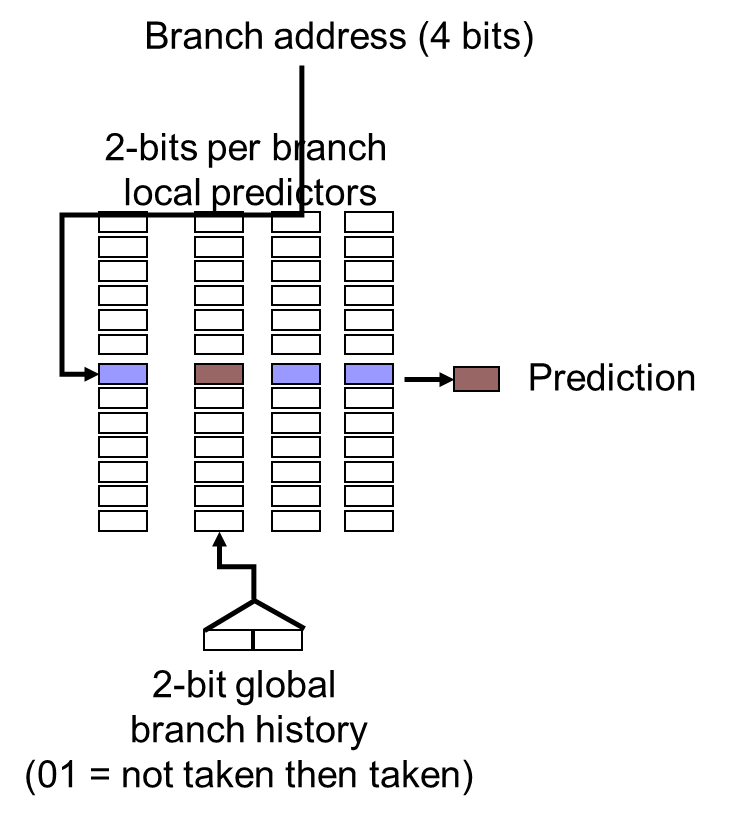
图为(2,2)预测器
流程
- 表示m条语句真实跳转情况的m位数据
- 根据比特串选择哪个预测器进行当前语句的预测
- 如果预测成功,失败 都检查预测器的值是否需要改变,根据状态转移图,如00改为01
Tournament Branch Predictor
Branch Target Buffer
Integrated Instruction Fetch Units
Return Address Predictors
TODO陈文智没讲这四部分
superscalar、 VLIW
通过硬件支持的ILP
- Basic 5-stage pipeline
- Extended to pipeline supporting FP operations
- Scoreboard
- Tomasulo Algorithm
- Branch predictor
- Hardware-based Speculation
- Explicit register renaming
终极目标CPI = 1 !!!
Multiple Issue Processors
可以实现CPI<1,有两种方法实现
- superscalar
- VLIW( Very Long Instruction Words )
superscalar
可变长度的指令,可以一次发射1、2…..n条
分类:
- Static Superscalar
- Dynamic Superscalar
- Speculative Superscalar
VLIW
定长的指令,一次只能发射2、3、4、、、条(可以有空的指令)
图为 一次发射5条指令
Multithreading
increases the throughput by better resource utilization.
multithread software
process
- Each process has its unique address space
- Can consist of several threads
thread
- has its own PC + registers + stack
- All threads within a process share same address space
- Private heap is optional
- increase concurrency and improve resource management.
multithread hardware
给每个线程独立的pc和register达到多线程效果,每个线程fetch到流水线里就可以独立跑
DLP(Data level Parallelism)
DLP
- Vector Processor
- GPU 多线程SIMD处理
SISD/SIMD/MIMD
SISD(一条指令操作一个数据)
ILP
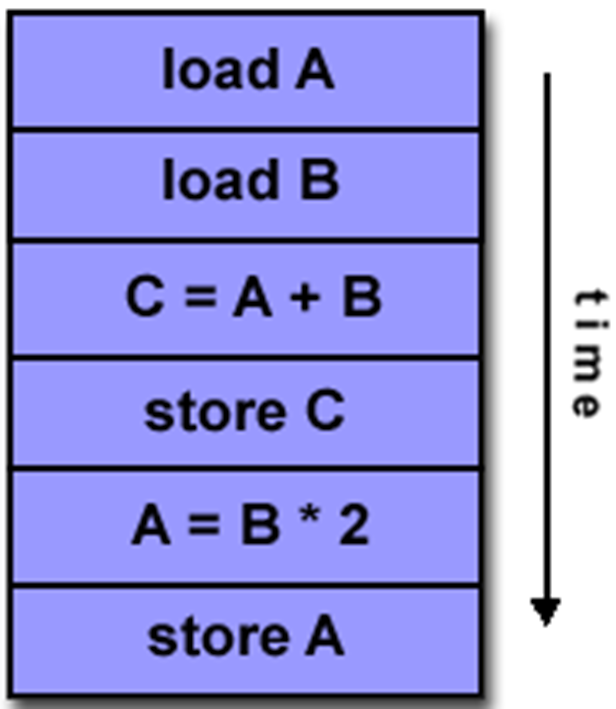
SIMD(一条指令多个数据流)
DLP
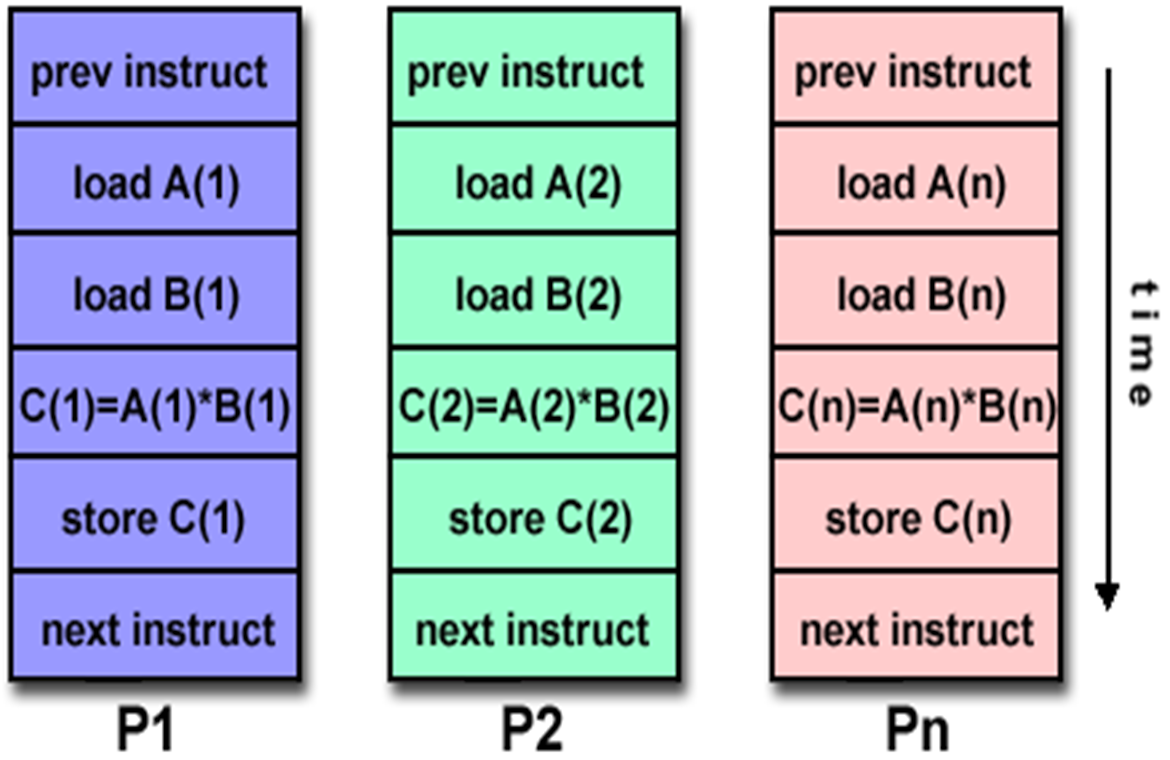
- 节能
- 顺序编程
- 可以向量计算
MIMD(不同核跑不同程序)
Vector Processing
Properties of Vector Processors
- Single vector instruction implies lots of work 一条指令包含了向量的多个数据
- result independent of previous result 向量各元素之间没有数据的关联
- Vector instructions that access memory have a known access pattern 行为可预测
- Reduces branches and branch problems in pipelines 不会出现预测失败(用loop计算的话)的情况
Types of Vector Architectures
memory-memory vector processors
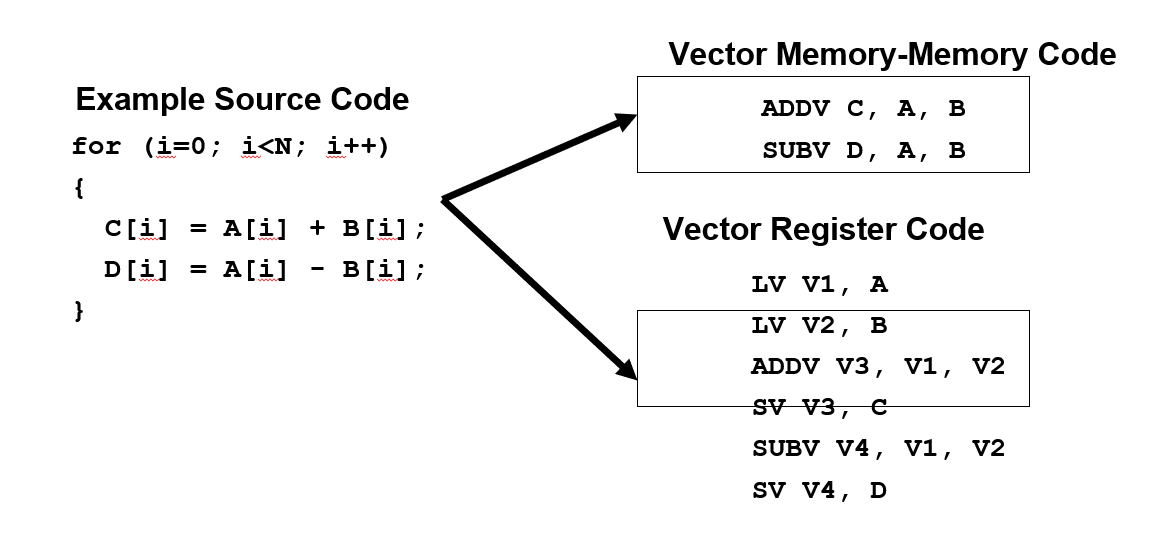
all vector operations are memory to memory 所有指令可以直接访问内存
vector-register processors
只有Load、Store可以访问内存
Components of Vector Processor
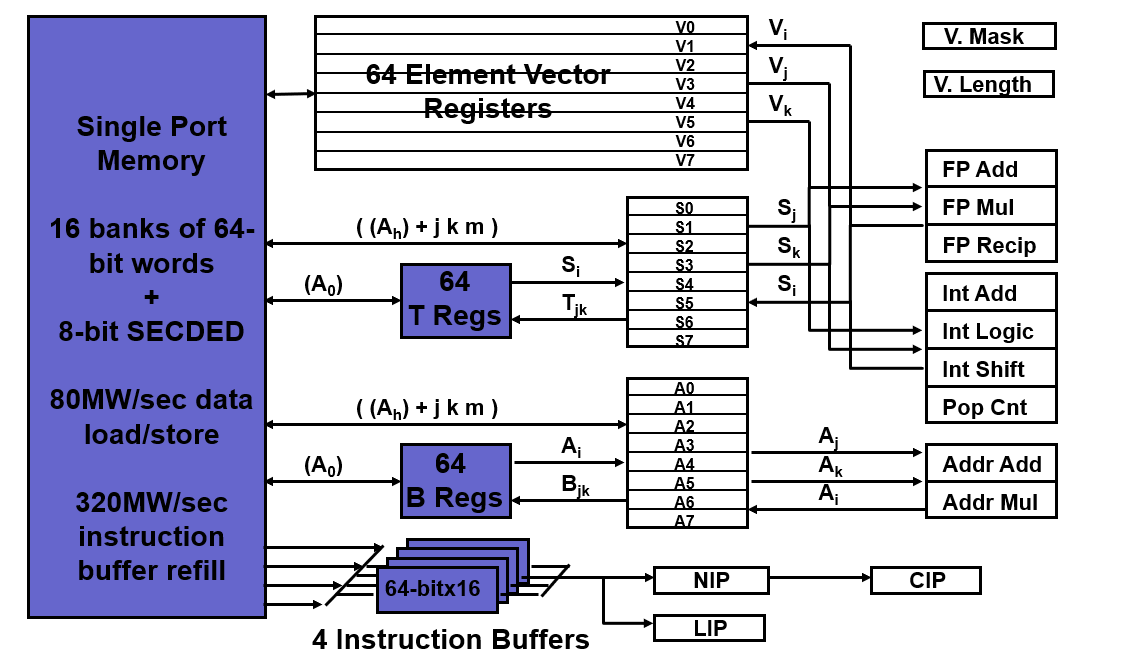
-
Vector Register: fixed length bank holding a single vector
-
has at least 2 read and 1 write ports
-
typically 8-32 vector registers, each holding 64-128 64-bit elements
-
-
Vector Functional Units (FUs): fully pipelined, start new operation every clock
-
Fully pipelined, start new operation every clock
-
Typically 4 to 8 FUs: FP add, FP mult, FP reciprocal (1/X), integer add, logical, shift;
-
may have multiple of same unit
-
-
Vector Load-Store Units (LSUs):
-
fully pipelined unit to load or store a vector;
-
Multiple elements fetched/stored per cycle
-
may have multiple LSUs
-
-
Scalar registers: single element for FP scalar or address
Cross-bar to connect FUs , LSUs, registers
Basic Vector instructions

Optimizing Vector Performance
- Vector Chaining
forwarding:

- Conditionally Executed Statements
是1的进行计算,是零的不用计算 only execute elements with non-zero masks
- Sparse Matrices
稀疏矩阵
- Multiple Lanes
利用性质:result independent of previous result 向量各元素之间没有数据的关联
Multiprocessor
MIMD 多核架构分类
Task Level Parallelism TLP线程级并行
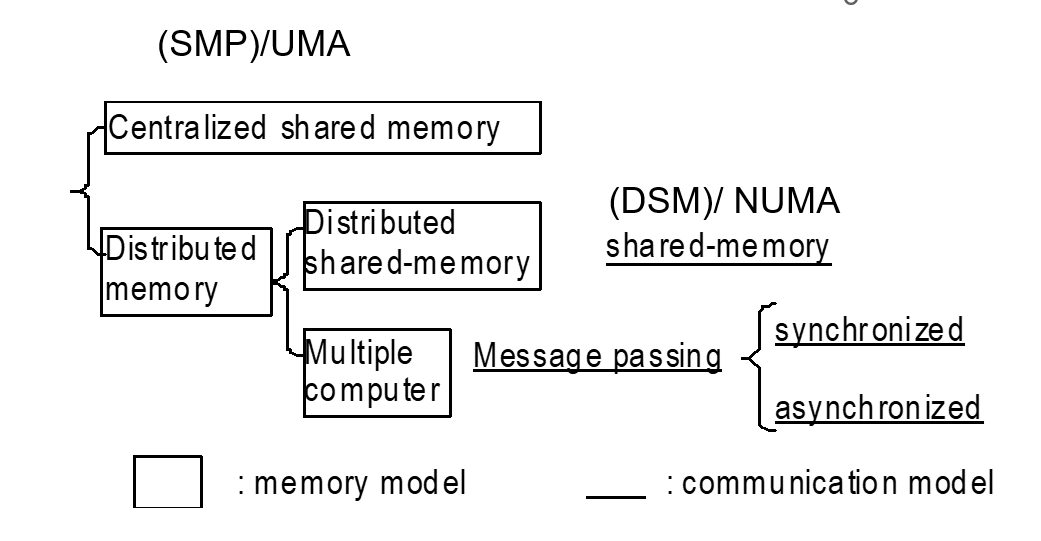
Centralized shared-memory multiprocessor (SMP/UMA)
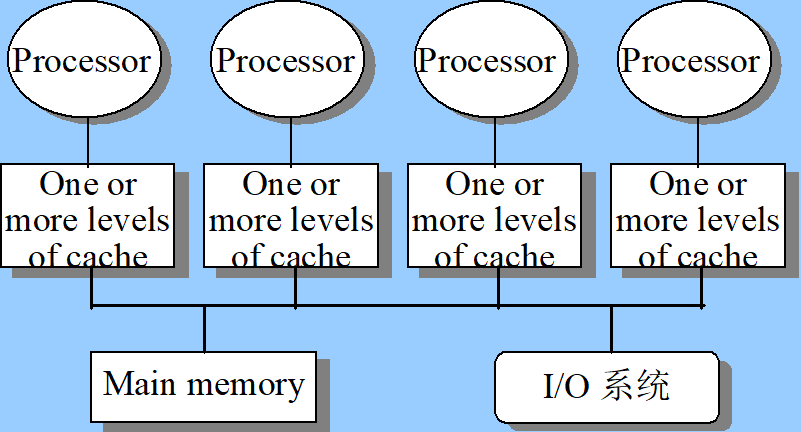
- 存储器main memory是集中共享的
- 通过总线连接
- 每个处理器都有自己的cache:cache了私有和公有的数据
- 节点数扩展性不大
distributed shared-memory multiprocessor(DSP/NUMA)
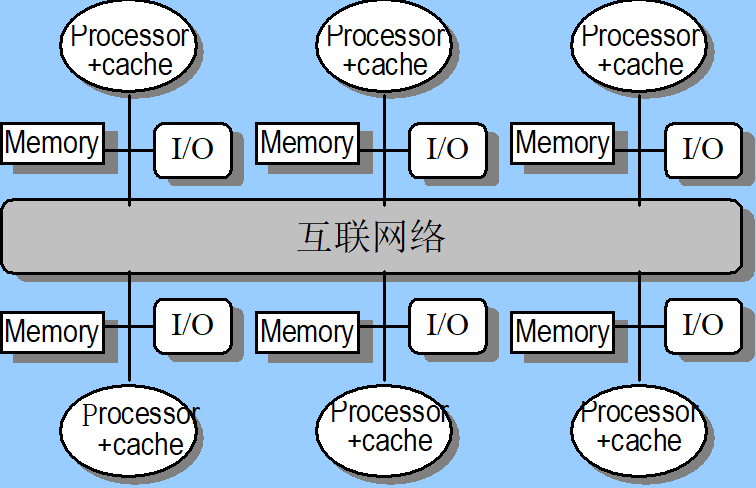
- 节点扩展性强
- 存储器是分布式的:两种方式实现(1)内存地址逻辑上分离,物理上连续 (2)内存地址物理、逻辑上都分离
- 通过网络来互联:处理器之间使用消息机制来访问对方的存储器
- 每个处理器都有自己的cache: cache只存私有数据会使性能降低;但是存公有数据就会产生一致性的问题;
Cache Coherence
前言:不管是多处理器还是单处理器,不管write策略如何,都可能会出现一致性的问题
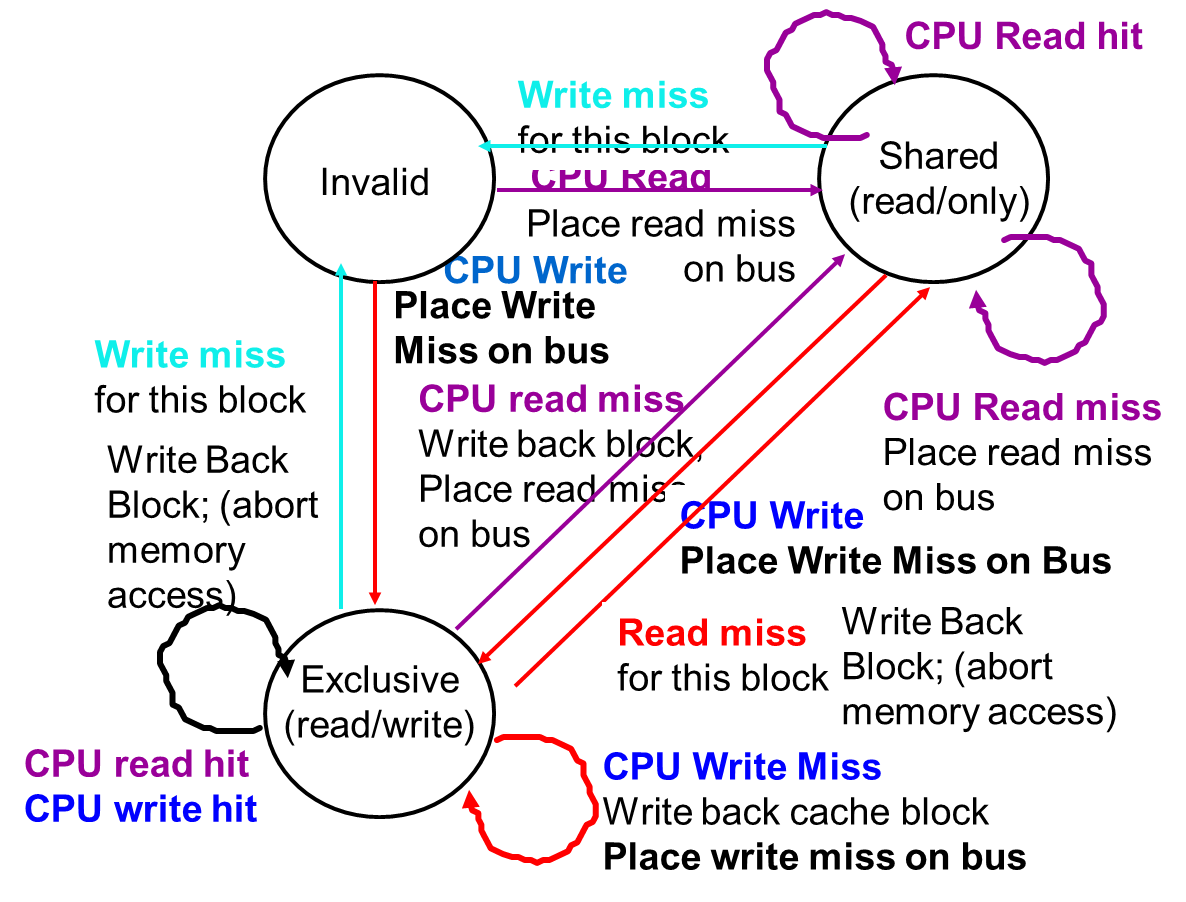
Snooping Solution (侦听协议)
更适用于总线结构,侦听协议分为两种:
Write Invalidate Protocol
写共享的数据,会在总线上发布无效的信号,传递到拥有此数据的cache,更新这些cache的此数据为无效
缺点:miss可能增多
Write Broadcast Protocol
写共享的数据,会在总线上发布广播数据的信号,传递到拥有此数据的cache,更新这些cache的此数据为最新值
缺点:代价大
Snoopy-Cache State Machine
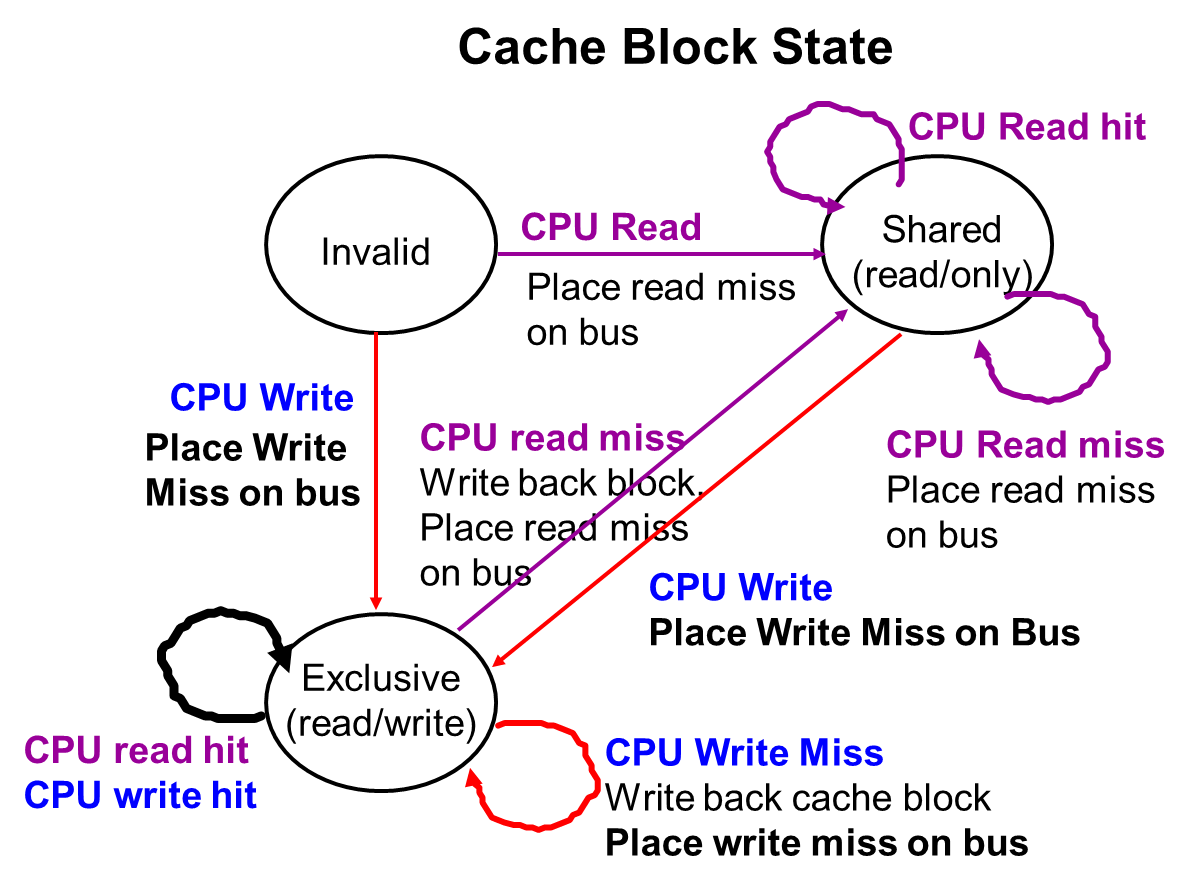
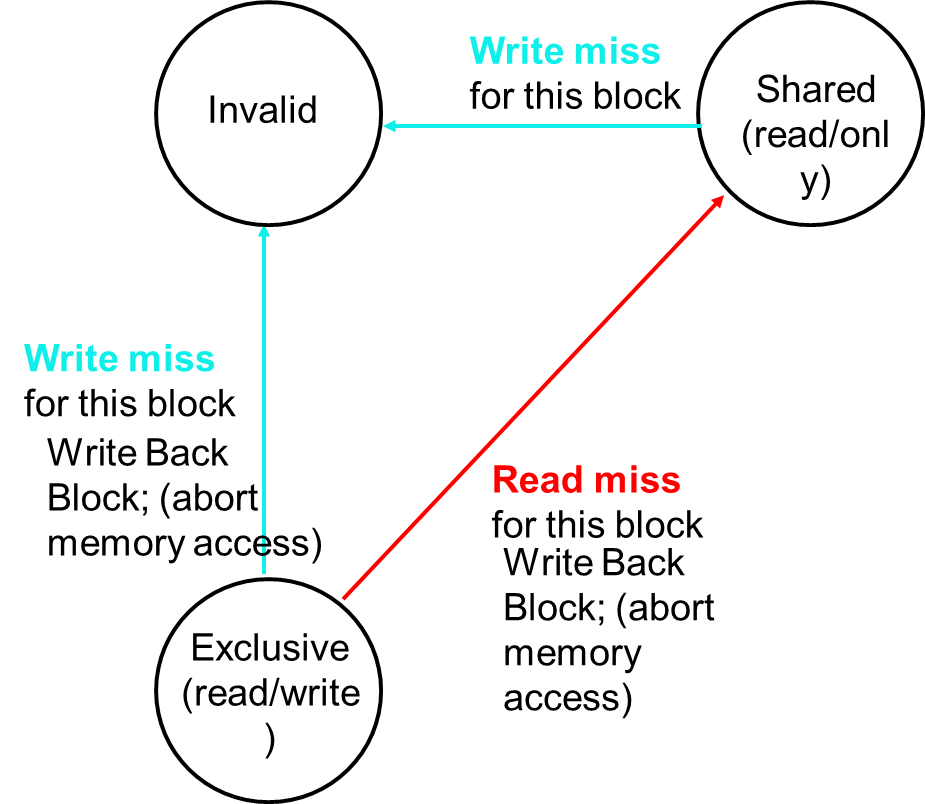
Directory-Based Schemes (目录协议)
更适用于分布式架构
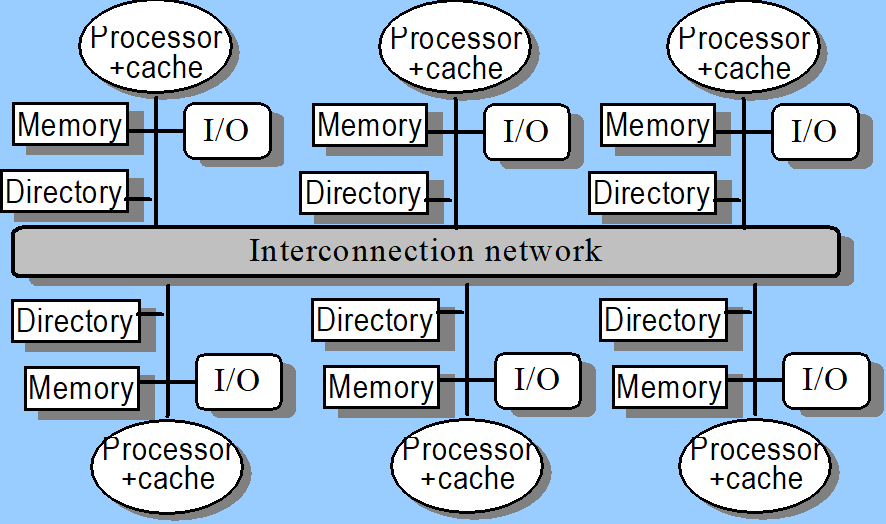
directory和cache都存放了数据的状态,directory存放的是本地memory数据的状态:有哪些是exclusive(被谁exclusive)哪些是share(被谁share)